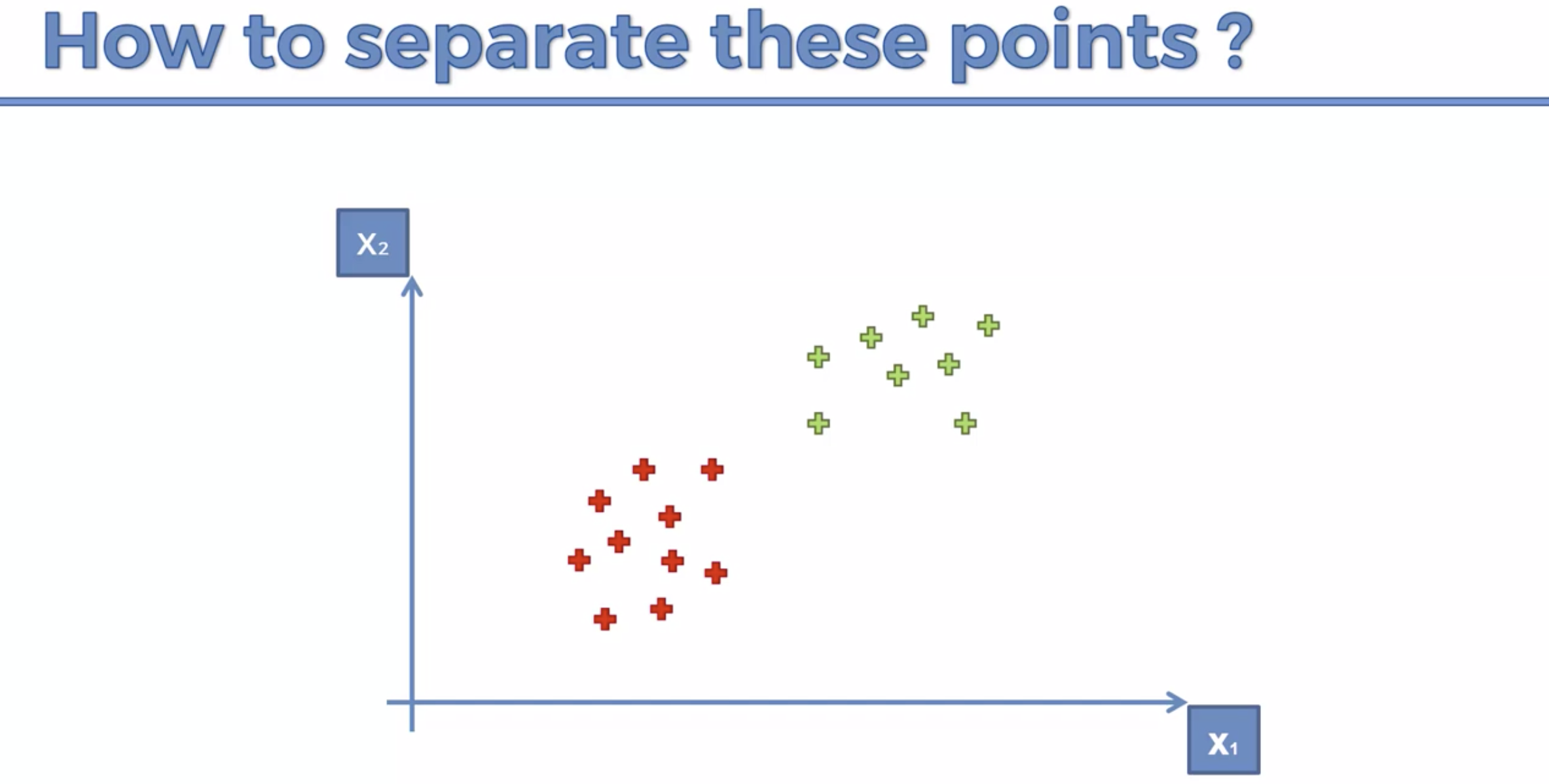
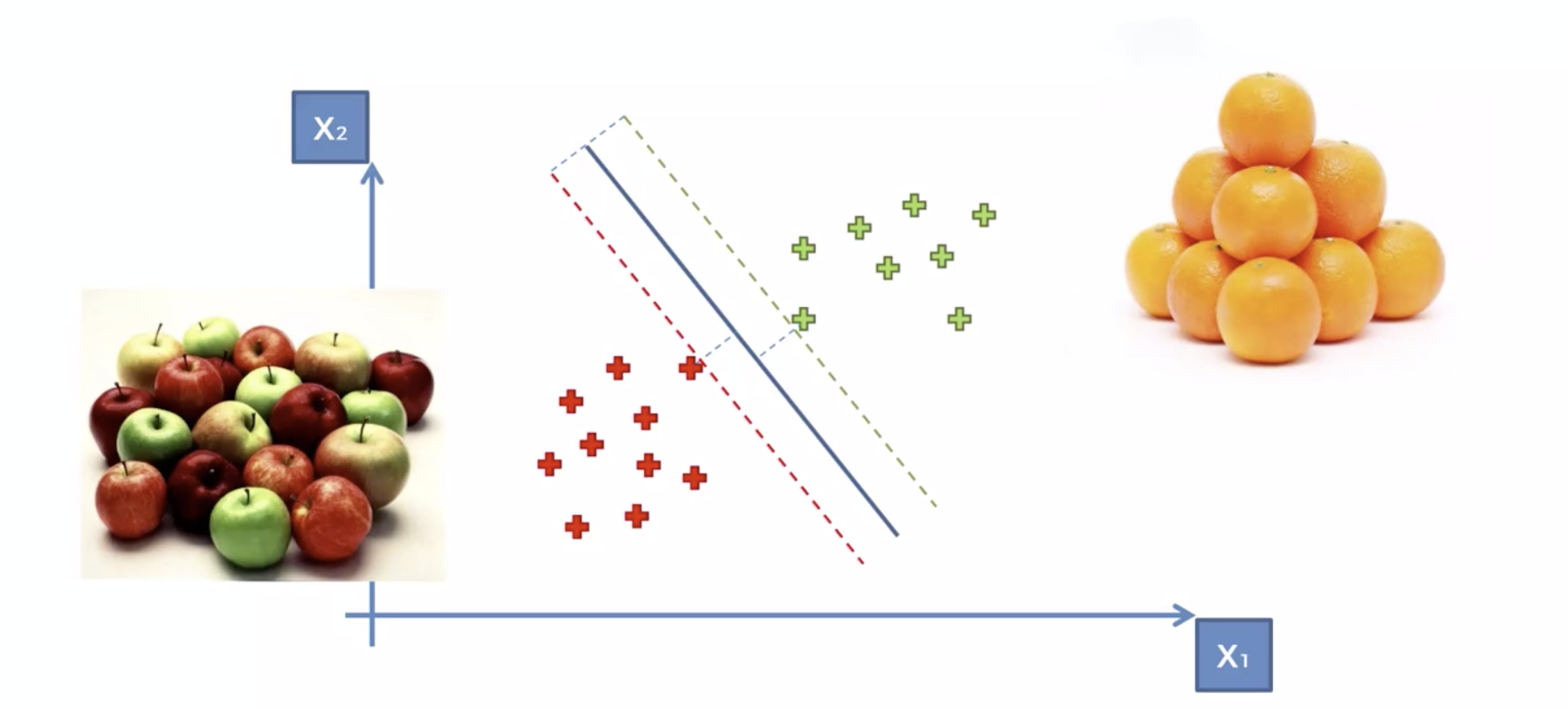
아래의 3개 의 선 모두, 분류하는 선이 모두 맞다. 그러면 어떤것이 더 정확할까?
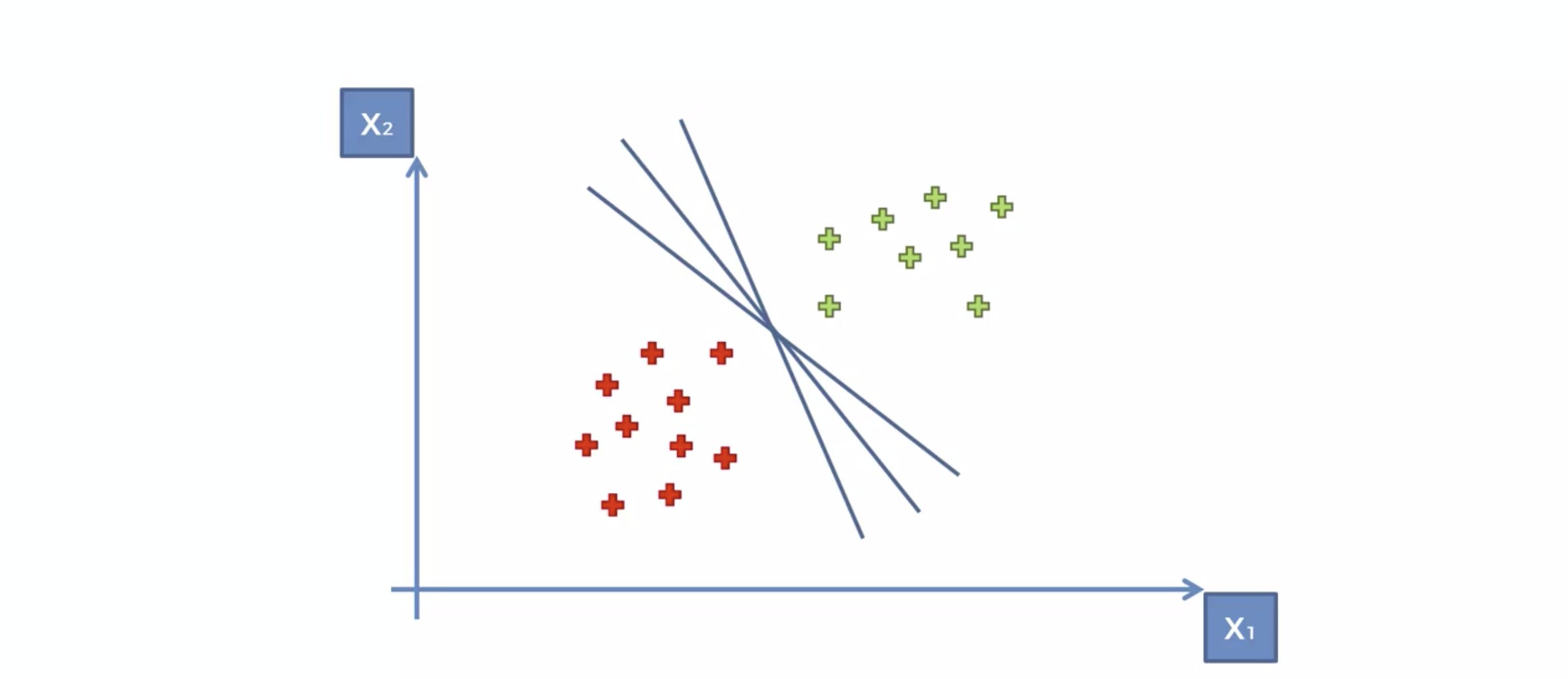
분류선에 가장 가까운 데이터들을, 가장 큰 마진(margin)으로 설정하는 선으로 결정하자.
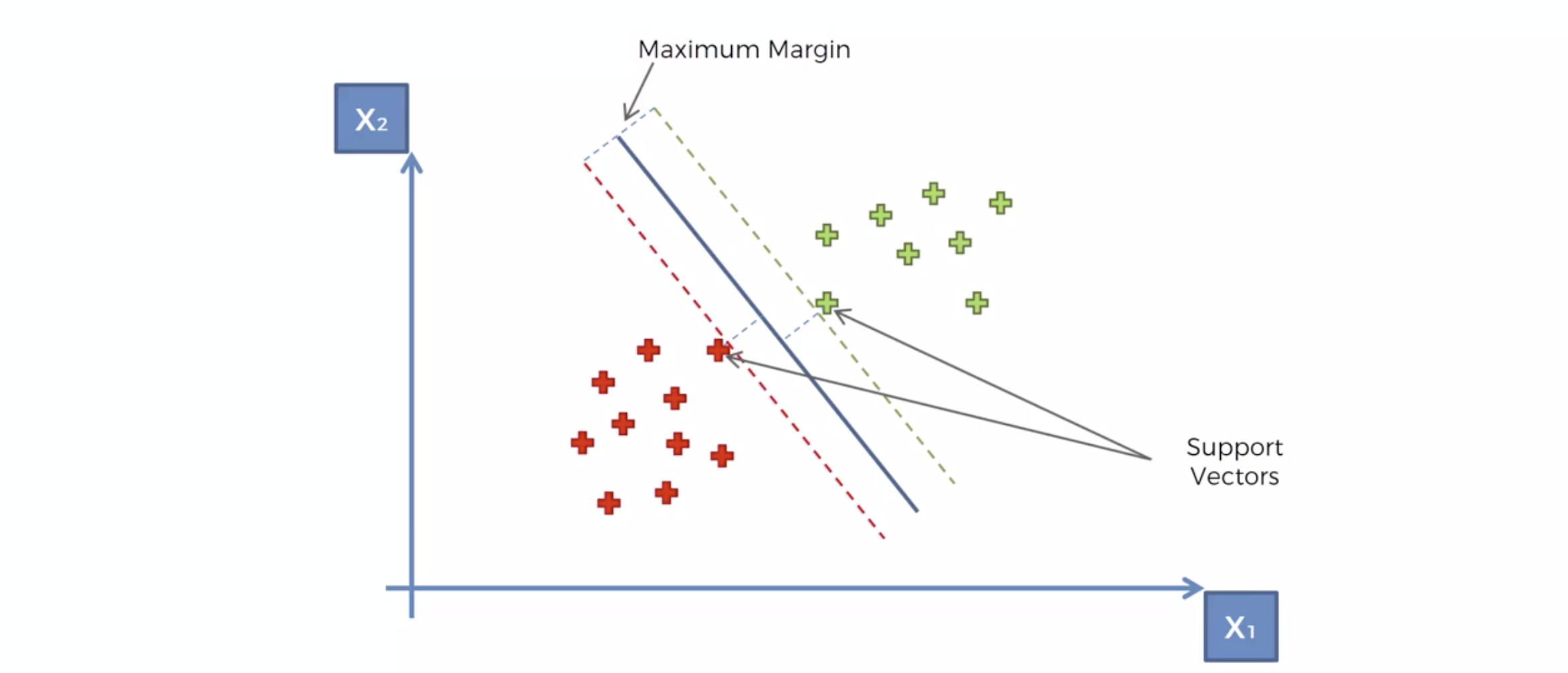
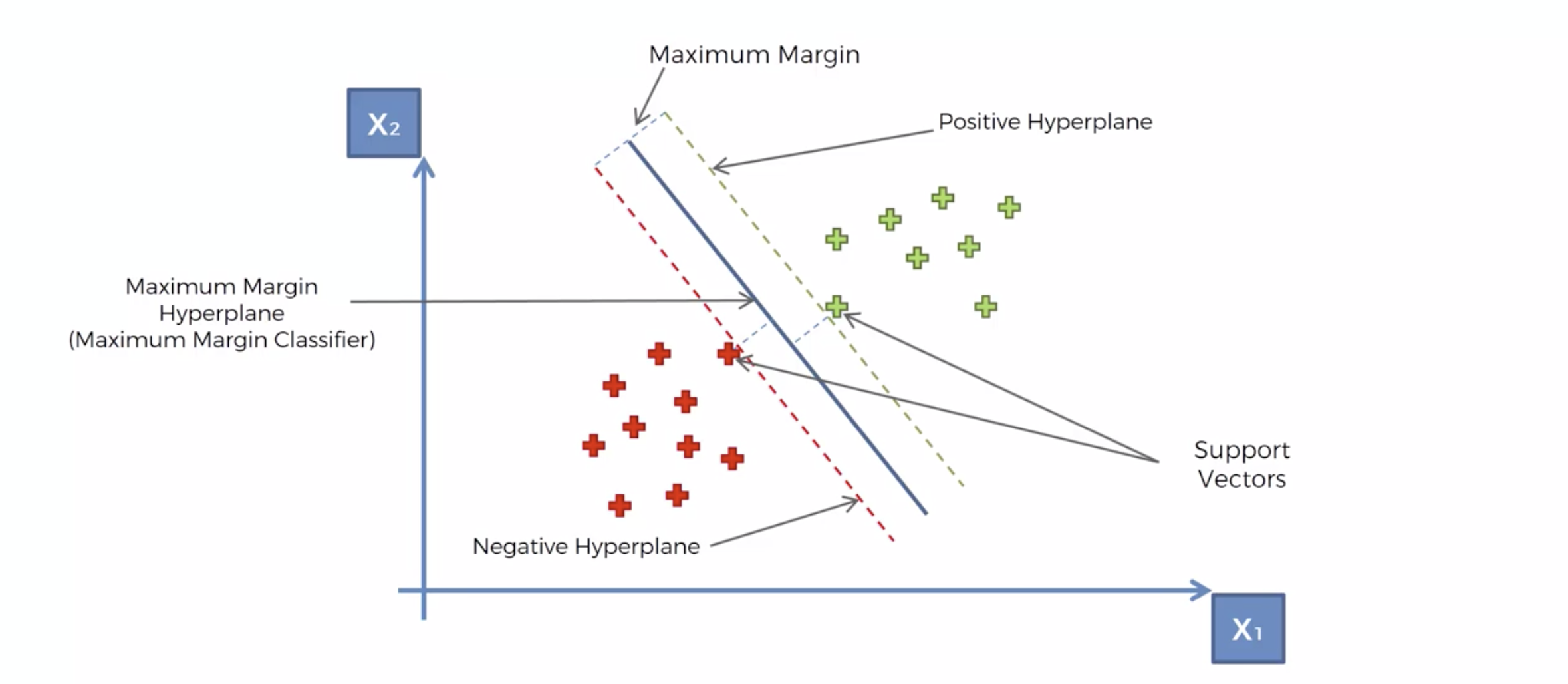
분류선을 Maximum Margin Classifer 라고 한다.
SVM은 다른 머신러닝 알고리즘과 비교해서 무엇이 특별한가?
사과인지 오렌지인지 분석하는 문제

일반적인 사과와 오렌지들은, 클래서파이어에서 멀리 분포한다.
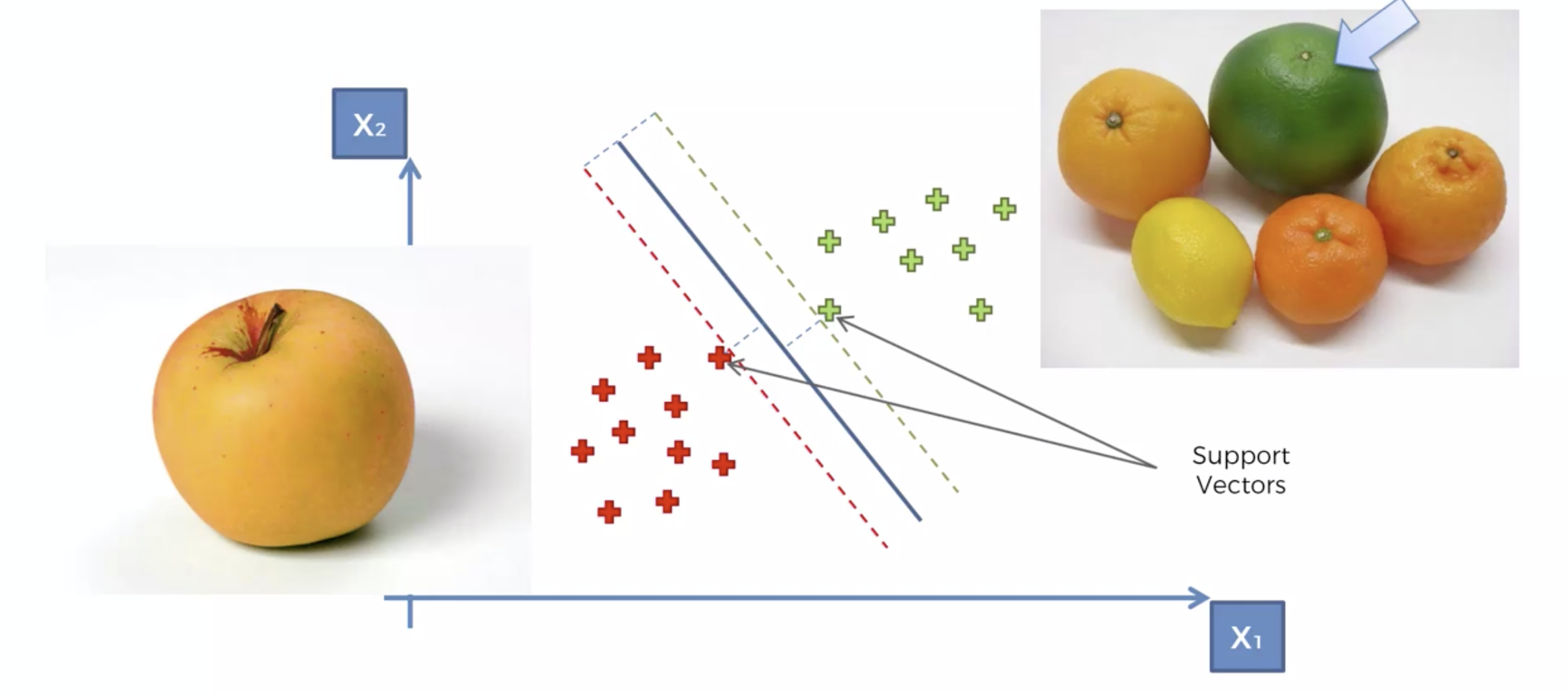
정상적이지 않은 것들, 즉 구분하기 힘든 부분에 있는 것들은 클래서파이어 근처에 있게 되며,
이 데이터들이 레이블링 되어 있으므로, Margin을 최대화 하여 분류하기 때문에, 특이한 것들까지 잘 분류하는 문제에 SVM 이 최고다.
Type Markdown and LaTeX: 𝛼2
# Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sb
# X를 피처스케일러 - 범위가 다르기 때문에 맞춰줌
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
# train/ test split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=3)
# 모델링: SVM 의 분류 문제에 적응하는 모델은 SVVM 입니다. C의 약자는 Classifier 의 약자.
from sklearn.svm import SVC
classifier = SVC(kernel = 'linear', random_state=3)
classifier.fit(X_train, y_train)
SVC(kernel='linear', random_state=3)
# 모델평가 : X_test를 예측하고, 컨퓨젼메트릭스로 검증
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
cm
array([[61, 4],
[13, 22]], dtype=int64)accuracy_score(y_test, y_pred)
0.83
# SVC의 파라미터로, kernel = 'rbf'로 설정해서 머신러닝 하세요.
classifier = SVC(kernel = 'rbf', random_state=3)
classifier.fit(X_train, y_train)
SVC(random_state=3)y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(y_test, y_pred)
cm
array([[58, 7],
[ 4, 31]], dtype=int64)accuracy_score(y_test, y_pred)
0.89
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=- 1, decision_function_shape='ovr', break_ties=False, random_state=None)
Cfloat, default=1.0
Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. The penalty is a squared l2 penalty.
kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, default=’rbf’
Specifies the kernel type to be used in the algorithm. It must be one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ or a callable. If none is given, ‘rbf’ will be used. If a callable is given it is used to pre-compute the kernel matrix from data matrices; that matrix should be an array of shape (n_samples, n_samples).
gamma{‘scale’, ‘auto’} or float, default=’scale’
Kernel coefficient for ‘rbf’, ‘poly’ and ‘sigmoid’.
- if gamma='scale' (default) is passed then it uses 1 / (n_features * X.var()) as value of gamma,
- if ‘auto’, uses 1 / n_features.
Changed in version 0.22: The default value of gamma changed from ‘auto’ to ‘scale’.
'AI 이론 > Classification (supervised)' 카테고리의 다른 글
| Stopwords (불용어) (0) | 2021.11.26 |
|---|---|
| [머신러닝] Decision Tree (0) | 2021.11.25 |
| [머신러닝] K-Nearest Neighbor (K-NN) (0) | 2021.11.24 |
| [분류 러닝] 성능 측정 => Confusion Matrix (0) | 2021.11.24 |
| [머신러닝] Logistic Regression (0) | 2021.11.24 |